8 並列処理ソフトウェアの課題と対策技術
8.1 はじめに
マルチコア上で動作するプログラムは、コアを有効利用するために並行性を持つ様に構成(Thread化)する。それらのスレッドは別なコア上で動作する場合、物理的に並列動作する。
このようなシステムで、プログラムの並列性を理解して設計する事は次の様な観点から必須となる。
- 計算資源の有効利用
- ソフトウェアの並列性に起因する不具合の回避
8.2 並列プログラムの課題
ソフトウェアを、マルチコアで動作させること、もしくはマルチコアで動作するように変換することを「並列化」と呼ぶ。最初に、ソフトウェアを並列化するための手法や開発プロセスの課題について説明する。ソフトウェアの並列動作可能な計算資源へのマッピングとして、計算資源の有効利用が課題とされている。また、並列プログラムは以下のような挙動理解が困難である。
8.2.1 非決定性
並列プログラムの挙動には「非決定性」を含む場合がある。非決定性を持つプログラムでは、状態遷移の分岐が排他的でない。これはテストプログラムや不具合事象の再現性が悪く、デバッグしにくい。
8.2.2 複雑性
並列に動作する別別のスレッドが別々の状態遷移を持つため、システムの状態はその組み合わせになり、複雑で、膨大な振る舞い空間をもつ。これはシステム挙動の網羅的な検証が困難である。
8.3 問題のある振る舞い
マルチコア上で動作する並列プログラムの挙動には非決定性が含まれる。
8.3.1 振る舞いの非決定性
プロセスPAとPBが並行に動作する場合、「可能な挙動」は組み合わせが膨大になりうる。
PA = ea1 -> ea2 -> ea3 -> Stop;
PB = eb1 -> eb2 -> eb3 -> Stop;
8.3.2 データ破壊・不整合
複数スレッドが共有メモリ領域を読み書きする場合に起きる。並列に動作する複数のスレッドが共有の記憶領域に対して同時に書き込むような場合に、データが適切に更新されず、矛盾・破壊する事がある。これではプログラムの機能(入出力仕様)が保証されない。データ破壊は同時書き込み時に起こる。また、データ不整合は複数のメモリ内の情報の間に成り立っていなければならない関係(条件)が崩れる。
8.3.3 デッドロック
並列に動作する複数のスレッドが共有の記憶域にアクセスするために組み込んだ「排他制御」が想定通りに動作せず、システムが停止してしまう。これではプログラムの可用性が保証されない。また、共有リソースのロックが外れなくなる。
次の例では、連続するタイミング1,2においてThread A,BがそれぞれリソースR1,R2を異なる順番でロックすることでデッドロックするケースを示す。
タイミング1:
ThreadAがリソースR1を利用(R1をロック)
ThreadBがリソースR2を利用(R2をロック)タイミング2:
ThreadAがリソースR2を使おうとしてR1のアンロックを待つ
ThreadBがリソースR1を使おうとしてR2のアンロックを待つ
<<<Deadlock>>>8.4 形式検証
形式検証では、対象システムの挙動をモデル化する。このモデルは、形式仕様記述言語(プログラムの構造を数学的な意味で厳密に記述するために設計された言語)で記述したモデルである。これにより、非決定的なモデルが表現でき、そのモデルに対して網羅的な検証が可能である。
挙動のモデルは「状態遷移」の考え方の数学的な表現。次の2種類が知られている。
8.4.1 オートマトン ( A = {S, s0, E, T} )
有限オートマトンを用いる
8.4.2 プロセス代数 ( X = A op B )
並行プロセスを代数的な操作ができる「式」として表現する事で、並行動作するシステムの振る舞いを解析する。プロセス代数(CSP等)で、並行動作するシステム同士が協調動作する事を表現するのに「チャネル」の概念を使う。ここで、プリミティブ要素として「同期チャネル」を用意しているが、拡張要素として、「通信バッファ数」を指定できるモデルもある。
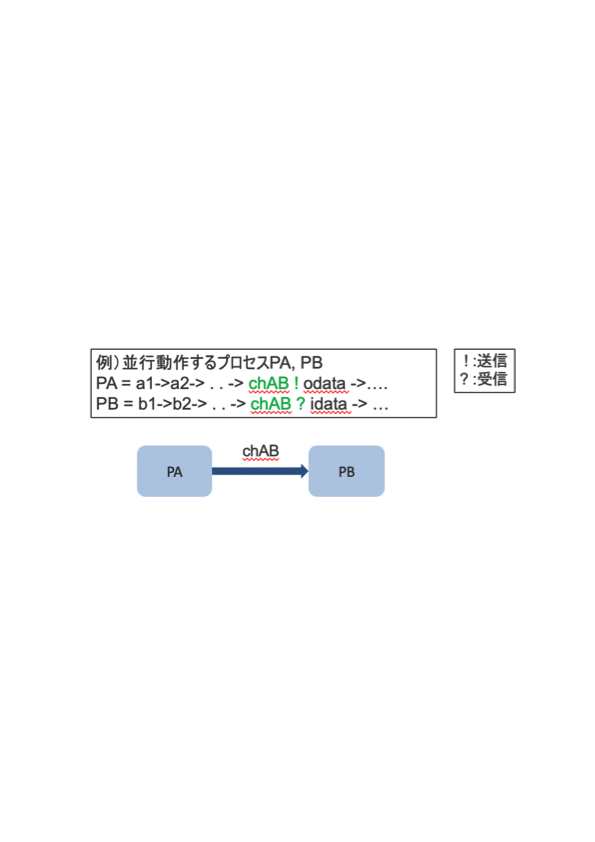
記述例
- プロセスPAとプロセスPBの並行合成演算
PA || PB- 仕様を表現したプロセス Specと設計を表現したプロセスDsgが「詳細化関係(refinement)を満たすか」
Spec <refine> Dsg8.4.3 現存するツール
| Name | Model | language | Distributed by | feature | |
|---|---|---|---|---|---|
| SPIN | automaton | Promela | Gerard J. Holzmann | Most measure | |
| NuSMV | automaton | SMV | ITC-IRST (Italy) | many model | |
| UPPAAL | Timed automaton | NTA | UP4ALL(Demmark) | Timed model Easy to use(GUI) |
|
| PAT | CSP(base) | CSP# | Semantic Engineering | Many model | |
| SCADE | Scade | Lustre | ANSYS/ESTEREL | Model Base | |
| Simulink Design Verifier | Simulink/Matlab | Simulink model | Mathworks | Model Base |
より詳細はWikipediaを参照
8.4.4 モデル検査ツール適用の流れ
- モデル作成
- 挙動のモデル
- 検証式(assertion)記述
- 要件由来(機能・非機能)など、システムが満たしているべき性質を記述
- 抽象的には以下のようなものが記述可能
- 到達可能性
- 安全性
- 他(Deadlockしない、Livelockしない、など)
8.5 適用事例の情報
- サイト
- IPA「報告書:形式手法導入課題を解決する「形式手法活用ガイドならびに参考資料」
- ディペンダブルシステムのための形式手法の実践ポータル/モデル検査(MRI)
- Paper
- 形式手法に基づく並行処理可視化ツールの紹介(産総研・磯部)
- モデル検査ツールの利用 マルチコア環境におけるタスク設計検証(藤倉インターフェース / CQ出版社)
8.6 プログラミング言語/ライブラリ
8.6.1 並列処理に向いたプログラミング言語
8.6.1.1 並列処理指向のプログラミング言語
並列処理に必要な要素を言語要素として持つ
- Thread生成
- 同期・通信
- 安全機構 (データ破壊防止等)
8.6.1.2 関数型プログラミング言語
- (より純粋な)関数内の変数はThreadSafe
- Closure
- 関数の論理構造の中に並列性が明示される
- 破壊的な代入が無いため、データフローは、関数の引数と返却値のみを追いかければよい
8.6.2 並列指向言語/ライブラリ
8.6.2.1 言語
- Go – Google
- Rust - Mozillaの公式プロジェクト
- Erlang – 公開されたEricsson内製言語
- Occam – Transputer/Inmos用の言語
8.6.2.2 ライブラリ
- OpenMP – Shared memory Base
- OpenMPI – Message Passing Base
- OSCAR API - OpenMP + α + β + …
- PPL(Parallel Patterns Library) – Microsoft
- TBB(Threading Building Block) – Intel
8.6.3 並列処理指向言語の例 – Go
- Kenneth Lane Thompson(Cの開発者)らによって開発された。
- 言語要素として Thread、Channelの概念を持つ。
8.6.3.1 Channel定義
プロセス代数(CSP)由来のもの。バッファサイズ指定が可能
ch := make(chan int, 8) // バッファサイズ8のint型チャネル8.6.3.2 Thread定義
定義した関数を「go」というキーワードを付けて呼び出す事でスレッド生成を意味する(「go routine」と呼ぶ)
go hello(); // hello 関数を別Threadで実行. helloは別途定義した関数
go world(); // world 関数を別Threadで実行. worldは別途定義した関数8.6.4 並列処理指向言語の例 – Rust
- Mozilla Researchの公式プロジェクト
- 速度、並行性、安全性を言語仕様として保証するC言語、C++に代わるシステムプログラミングに適したプログラミング言語を目指しており、強力な型システムとリソース管理の仕組みにより、メモリセーフな安全性が保証されている。
「所有権(ownership)」概念の言語要素化
→ 安全でなければコンパイルが通らない
8.6.4.1 Channel定義
let(tx, rx): (Sender<i32>, Reciever<i32>) = mpsc::channel();8.6.4.2 Thread生成
let child = thread::spawn(move || {<Thread手続き本体>})8.6.5 マルチスレッド/通信 API
- マルチコアの活用のためにはプログラムが複数の並列実行可能な単位(Thread)に分割されている必要がある。プログラムをそのように構成するためには、Threadの生成/開始のようなThreadの実行制御に関わるものと、仮に共通にアクセスできるメモリがない場合に通信可能な、「Thread間通信」が実現できることが好ましい。
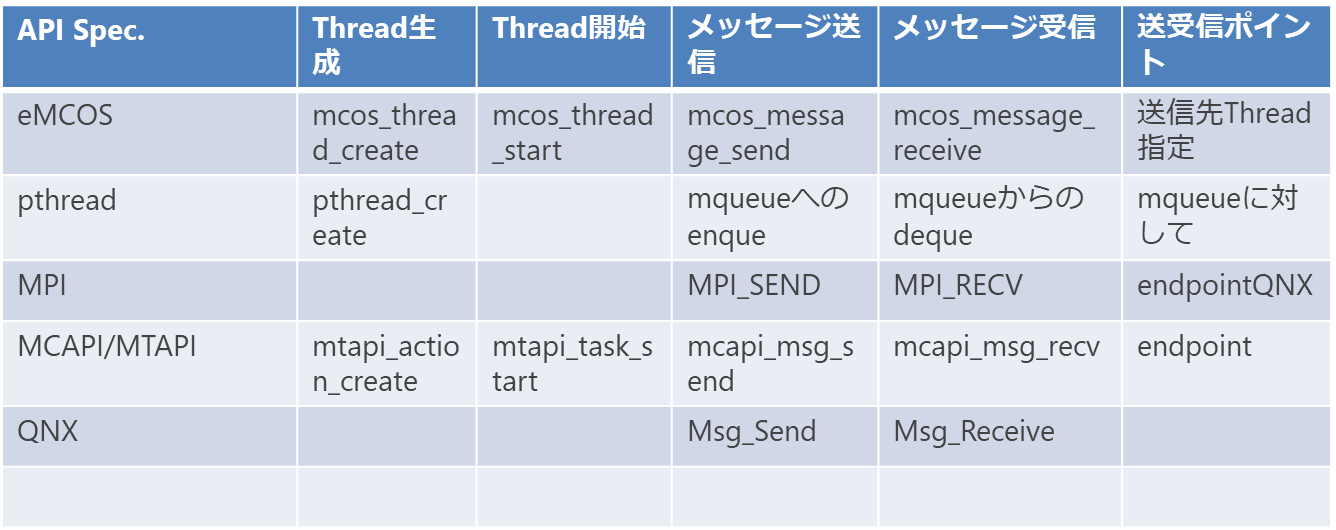
8.6.6 メッセージ送受信API
- 2つのEnd-Pointを指定し、「チャネル」オブジェクトを定義し、それに対して送受信する。
8.6.6.1 チャネル定義
EndPoint ep1, ep2;
Channel ch = new Channel<DataType>(ep1, ep2);8.6.6.2 送受信
DataType data;
send(ch, data); // Code in Thread 1
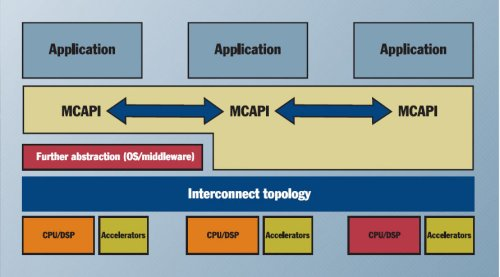
receive(channel, &data); // Code in Thread 28.6.7 参考情報(MCAPI)
- MCAPI - The Multicore Association
- Wikipedia
- MCAPI事例(Mentor Graphics)
8.7 マルチコア対応RTOS
8.7.1 マルチコアに対応したOSの機能
- Thread-Core Affinity (Static)
- Configurationによってあらかじめ指定
- Thread-Core Migration (Dynamic)
- 動的にCore割り当てを変える事ができる
- Message Passing
- スレッド間通信機能
8.7.2 MulticoreOSの特徴(動作モデル)
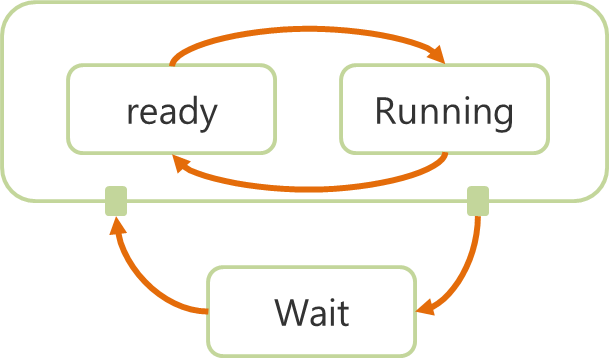
遷移イベントはアプリケーションによるOSのAPIコール
- Single Coreの場合
- Runningになれるタスクは1個
- Multi- Core(N-Core)の場合
- RunningになれるタスクはN個
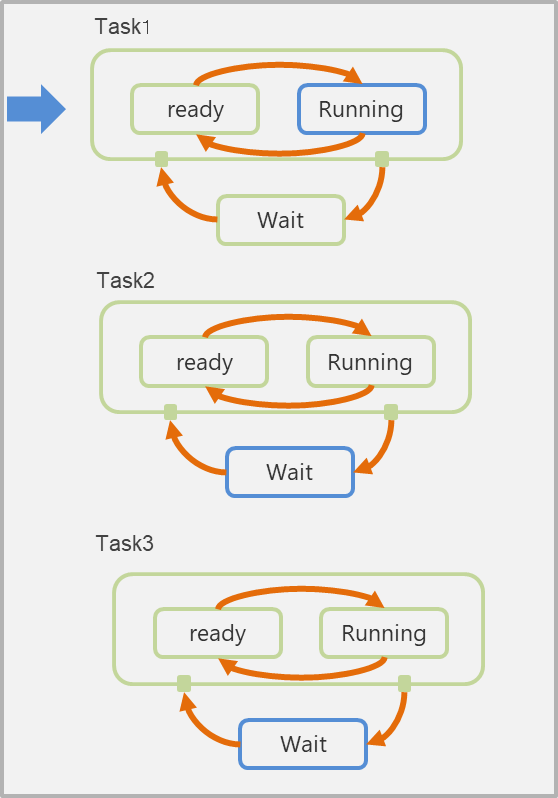
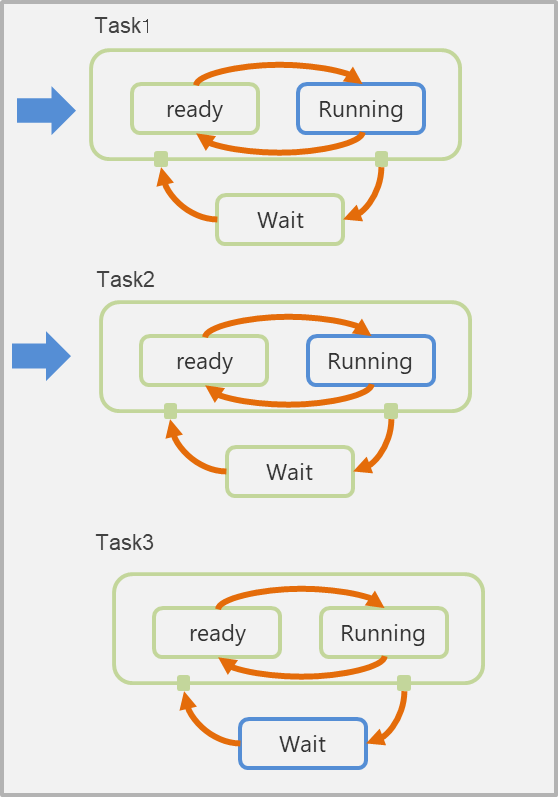
8.7.3 Single Core 3 task
- Single Core - 3task
- 優先度 : task1 > task2 > task3
- 制約
- あるタイミングでRunningになれるタスクは最大1つ
- もっとも優先度が高いreadyタスクがRunningになる
- readyタスクがあるのにRunningタスクがないことはない
8.7.4 2 Core 3 task
- Single Core - 3task
- 優先度 : task1 > task2 > task3
- 制約
- あるタイミングでRunningになれるタスクは最大2つ
- もっとも優先度が高いreadyタスクがRunningになる
- readyタスクがあるのにRunningタスクがないことはない
8.7.5 マルチコア対応RTOSの例
- eMCOS
- QNX
- POSIX対応OS (Posix Thread)
- TOPPERS/FMP
8.8 設計パターン
8.8.1 設計パターンとは
ソフトウェアのアーキテクチャ、デザイン、コーディングなどに対して、解決策としてのパターンを共有する。パターンはお互いに関連しあい、連携して利用されるパターン言語を形成する。
代表的な設計パタンのルーツは次の通り。現在は様々な領域でのパターン活動がある
- Pattern Language(Christopher Alexander )
- Software Design Pattern (GOF ※)
- Pattern Oriented Architecture Pattern (bushman)
- Taming Java Threads (Allen Holub)
※ Eric Gamma, Rechard Helm, Ralph Johnson, john Vissides



8.8.2 並列化ソフトウェア設計パターン
マルチ/メニーコアを利用したハードウェア上で動作する「並列処理ソフトウェア」に対しても、この「パターン」の蓄積・共有が有効だと思われる。
これらの設計パターンを用いる動機は、起こって欲しくない「設計由来の問題」をなくしたいことである。
- デッドロック
- 共有データの破壊
- 理解しがたい複雑さ
- デッドライン違反
- より効率的に処理を構成したい
- 複数コアの有効活用
- 無駄な通信を少く
- コア数非依存アルゴリズム(スケーラブル)
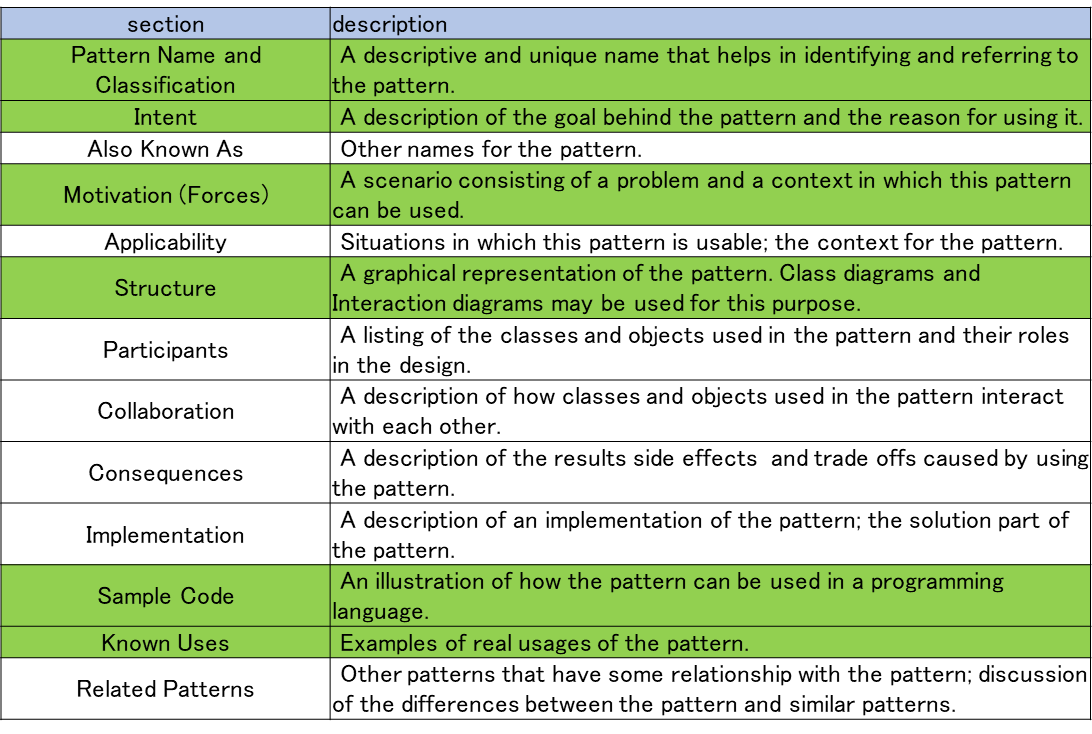
8.8.2.1 Pattern Template
活用可能なパターンカタログを作るために以下のような項目がそろっているのが望まれる
8.8.2.2 Pattern Example (From Eun-Gyu Kim / 2004)
http://snir.cs.illinois.edu/patterns/patterns.pdf
8.8.2.3 Concurrency Patterns (POSA2)
ソフトウエアアーキテクチャパターンの書籍(POSA:Pattern Oriented Software Architecture)中に並列処理パターンもいくつか紹介されている。

8.8.2.4 Intel – Design Pattern
Intel発信の情報
https://software.intel.com/en-us/node/506112
以下のようなパターンが紹介され、それをどの様に実装するか解説されている
- Agglomeration
- Elementwise
- Odd-Even Communication
- Wavefront
- Reduction
- Divide and Conquer
- GUI Thread
- Non-Preemptive Priorities
- Local Serializer
- Fenced Data Transfer
- Lazy Initialization
- Reference Counting
- Compare and Swap Loop
- General References
8.8.2.5 Structured Parallel Programming
- Subtitle : Patterns for Efficient Computation
- Michael McCool, Arch D. Robinson, James Reinders
並列プログラムを構成するためのパターンを紹介し、後半にはそれらを使った並列アルゴリズムの解説を行っている
8.8.2.6 anti-pattern
アンチパターン (英: anti-pattern) とは、ある問題に対する、不適切な解決策を分類したものである。 語源は、ソフトウェア工学におけるデザインパターンである。 主に失敗した開発プロセスに焦点を当てて失敗に陥るパターンを類型化する。 そうすることで、そのような事例の早期発見と対応策に関しての提案を目的とする。
マルチコア・システム開発に置いても、さまざまな不具合事象をパターンとして整理する活動を行う事で、同様の効果を期待できる。
8.9 並列化支援技術
マルチコアプロセッサと並列指向の言語やライブラリが与えられただけでは、それを有効活用するソフトウェアを構築するのは簡単ではない。
現状はある程度専門的なエンジニアがこれらを担っている。今後は、マルチコアを活用するソフトウェアをより多くのエンジニアが開発できるように、つかえる支援ツールの充実が望まれる。
8.9.1 並列化支援環境
並列化されていないプログラムのどこが並列化可能か、並列化する事による性能改善への寄与が大きいかといった情報を開発者へ提示。Threadプログラミング支援。
8.9.2 自動並列化技術
並列化されていないプログラムをスレッドライブラリなどを利用した並列化されたプログラムに変換する。
それにあたって、並列化されていないプログラムを解析(基本的にはデータフロー解析)して並行動作可能部分を抽出しスレッド化プログラムとして再構成する。さらに、限られたコア数に対してそれらのスレッドを割り当て配分する。
- CUDA – nVidia
- GPGPU向け
- OpenCL - Khronos Group
- Embedded Profile (組み込み向け)
- Intel Parllel Studio
- 統合開発環境として提供
- Eclipse Parallel Tools Platform (PTP)
- MPI, OpenMP, UPC(Unified Parallel C), OpenSHMEM ,OpenACCをサポート
8.9.3 自動並列化技術(具体例)
- eMBP( eSOL ) based on MBP ( Nagoya Univ.)
- Input : (Simulink Block Model , C Code generated by Embedded
- Output : Parallelized C Code (use multi-thread library)
- SILEXICA (SILEXICA)
- Tool Set for support parallelization
- Automatic Parallelization Compiler
- OSCAR (waseda Univ)
- C source -> Parallelized C (with OSCAR API)
- Intel Compiler
- C source -> Parallelized C(with openMP)
- (--parallel option)
- Solaris Stuio Fortran (Loop optimizatation)
- -autopar option
- PLUTO (Not general)
- Automatic parallelizer and locality optimizer fo raffine loop nests
- http://pluto-compiler.sourceforge.net/
- OSCAR (waseda Univ)
8.9.4 自動並列化の考え方
- 入力:並列化されていないプログラム
- 出力:並列化(Multi-Thread化)されたプログラム
- 並列化プロセス:
- データフロー解析
- 変数の代入関係を解析し、処理単位のデータ依存グラフ、タスクグラフを抽出。グラフ構造から並列可能な部分(ノード)が分かる
- コア割り当て
- ノード(タスク)が動作するコアを割り当てる。
- 並列化コード生成
- 別なコアに割り当てられた処理単位は別なスレッドとして動作するようなマルチスレッド・コードとして生成する。
- データフロー解析
- 並列化のゴール
- 処理速度の向上(処理時間を最小化)
- 低消費電力化(プロセッサの消費電力を最小化)
- 上記2つのゴール指標はトレードオフ
8.9.5 モデルベース並列化技術
- 入力
- データフローとして解釈できるモデル
- そのモデルに対応して作成/生成されたプログラムコード(C言語プログラムなど)
- 出力
- Thread化されたプログラム
- Threadへのコア割り当て情報
- 並列化プロセス
- データフローはモデルから取得
- 負荷分散、クリティカルパスなどの制約を満たすコア割り当てのルールを適用する
8.9.6 MBDは並列設計に利用可能
モデルベースの設計ツールが対象としている「モデル(ソフトウェア観点)」には、「データフロー」モデル、および、「状態遷移モデル」をがあり、これらをグラフィカルエディタなどの支援のもとに設計すると、そこから並列性を自動抽出することが可能となる。
- データフロー
- Matlab/Simulink
- LabView
- 状態遷移モデル
- Stateflow
- EHSTM
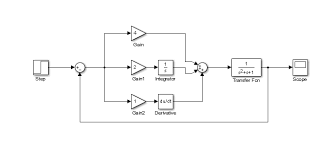
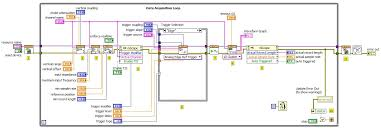
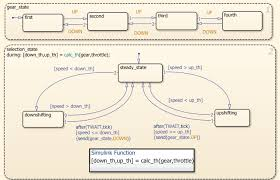
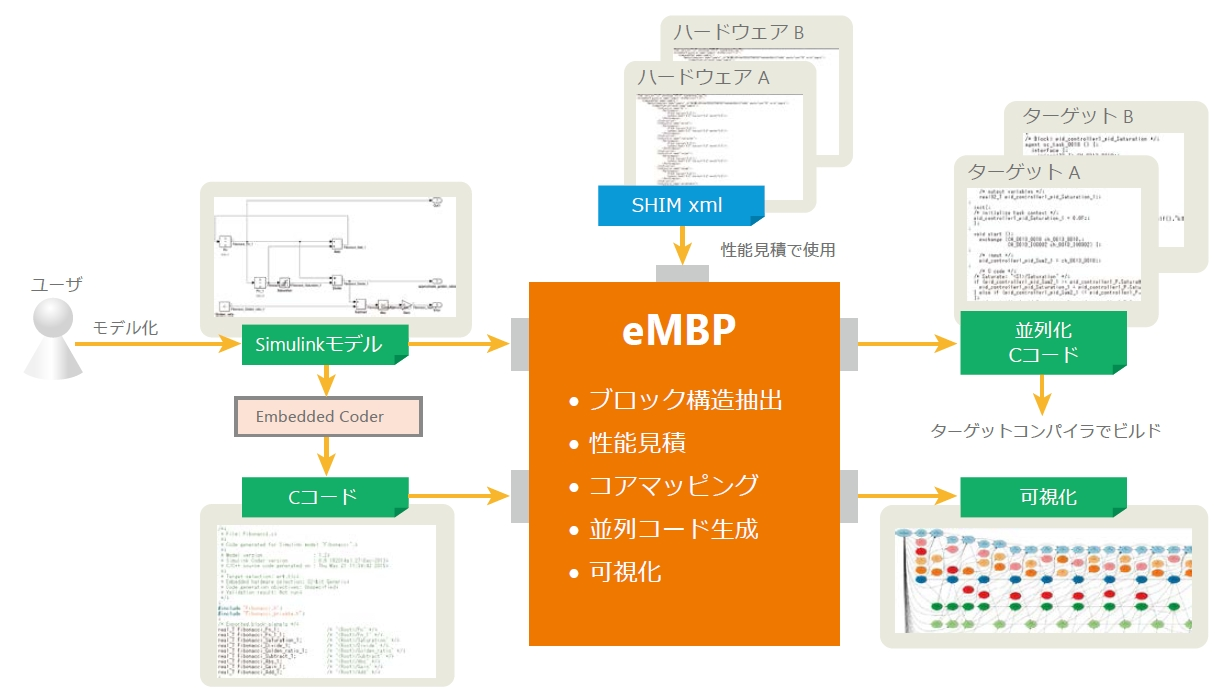
8.9.6.1 MBDにおける並列化の例(eMBP / eSOL)
SimulinkモデルとSimulinkモデルから生成されたCソースコードから並列化(Thread化)されたCソースコードを出力。
Threadのコア割り当てのためにSHIM(IEEE Std 2804)を利用した性能見積もりを行う。
8.10 トレースフォーマット
マルチコア環境でのプログラム・デバッグでは、ステップ実行やブレークポイントを利用した操作でのデバッグが難しい。そこで、タイムスタンプのついたトレースをとり、実行後に可視化などをする事で現象分析する事が有効となる
しかし、可視化機能、解析機能などを持ったツールはトレースフォーマットに依存したものになるため、標準的なフォーマットが必要となる。
8.10.1 トレースフォーマットCTF
- フォーマット名: CTF(Common Trace Format)
- 対応ツール
- TraceCompass
- Eclipse-plug-in
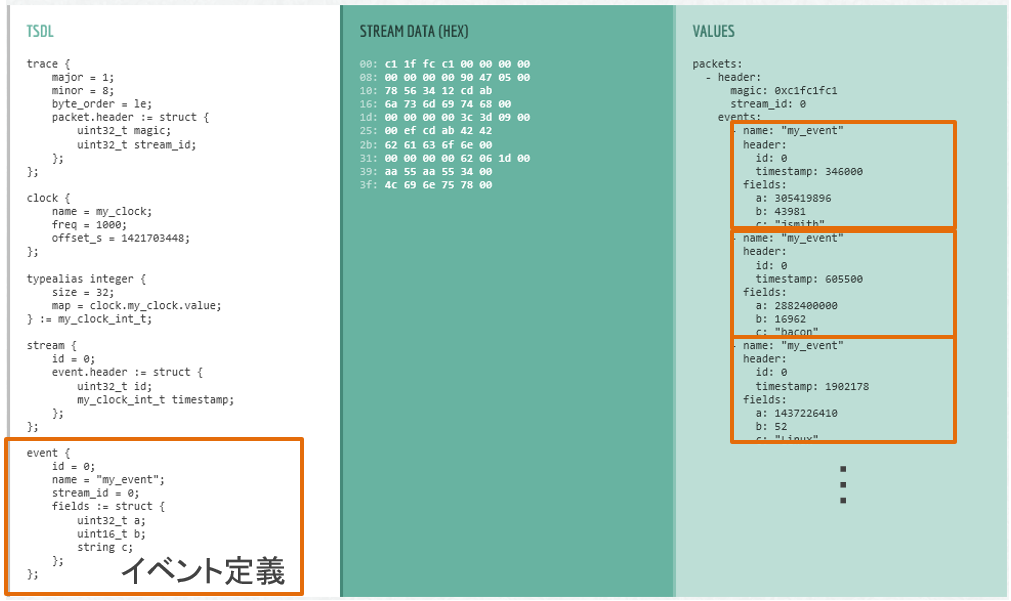
8.10.1.1 CTF特徴
- 対象ファイルフォーマット
- トレース要素定義ファイル(DSL) meta
- イベントを定義
- 対象ファイル
- 計測データ
- トレース要素定義ファイル(DSL) meta
- MCAからも参照されている
- TOOLS INFRASTRUCTURE WORKING GROUP (TIWG™)
8.10.2 可視化技術
8.10.2.1 CTF対応ツール
- TraceCompass
- Eclipse-plug-in
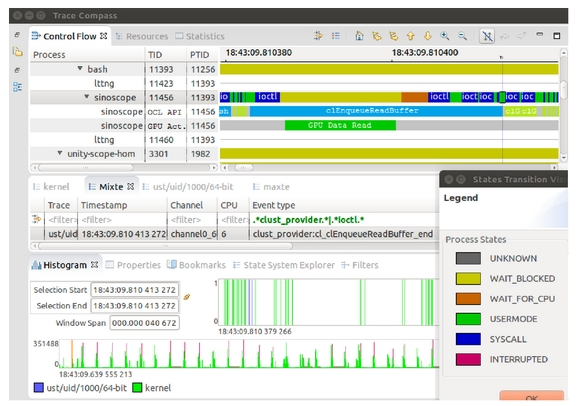
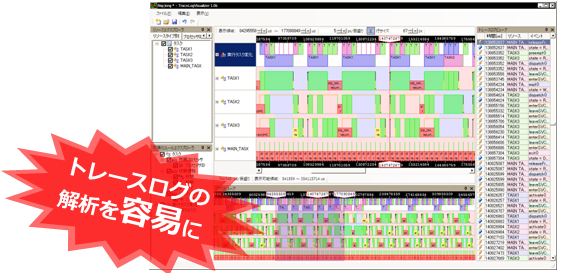
8.10.2.2 TOPPERS/TLV
- Trace Log Visualizer
- https://www.toppers.jp/tlv.html