1 <並列化フロー>完成度の高いマルチコアソフトウェアを効率よく作成するための開発手順
従来の製品開発プロセスの下でマルチコアソフトウェアの完成度を高めようとすると、いくつかの課題に突き当たるが、その中でも特に大きな課題は「並列性能の確保」と「品質の確保」だろう。
並列性能は、マルチコアのハードウェアアーキテクチャ、その上で動作するソフトウェアの構成や処理特性、およびコーディングスタイルなどに左右される。期待する性能を確保するためには、これらを総合的に勘案したシステム設計、および実際にソフトウェアを並列化し、性能を確認するための手段が必要になる。一方、高い品質を確保するためには、テスト環境やテスト手法の見直しが求められる。場合によっては、従来のプロセスに手を加える必要があるかもしれない。
本章では、これら二つの課題のうち、特に並列性能の確保に有効なマルチコアソフトウェアの開発手順について説明する。
- 本章の対象読者
- 知識・経験:レベル1(入門者)シングルコアの知識・開発経験のみ
- プロセス :設計、実装、テスト
- ドメイン :組込み全般
- キーワード :タスク、性能解析、依存解析、デバッグ、プロファイリング
- 本章を読んで得られるもの
- マルチコア向けにソフトウェアを並列化する手順が分かる。
- ソフトウェアの並列化に際して確認すべき事項や開発環境の概要が分かる。
1.1 ソフトウェアをどのように並列化するのか
ソフトウェアを、マルチコアで動作させること、もしくはマルチコアで動作するように変換することを「並列化」と呼ぶ。最初に、ソフトウェアを並列化するための手法や開発プロセスの課題について説明する。
1.1.1 並列化の粒度
並列化の粒度について説明する。なお第1部では、OSを採用するしないにかかわらず、組込みソフトウェアシステムにおいて処理する仕事の実行単位を「タスク」と呼ぶ。
マルチタスクの組込みソフトウェアシステムを並列化する際には、どのような単位(粒度)でソフトウェアをコアに割り振るかという点で、いくつかの選択肢がある。
1.1.1.1 タスク内並列処理
一つのタスクの中で同時に実行できる処理を抽出し、異なるコアに割り当てる。並列化できる単位はソフトウェア内のあらゆる処理になるため、並列化効率を最大限に高められる。
タスク内の処理の中から並列実行できる処理を抽出するのは人手では困難。自動並列化ツールなどの支援が必要になる。

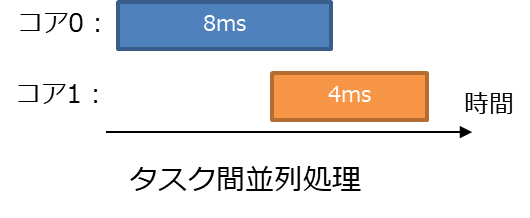
1.1.1.2 タスク間並列処理
異なるタスクを異なるコアに割り当てる。タスク間の依存関係を考えて時間とコアの配分を考える必要はあるが、タスク内並列処理より難易度が低い。
並列化できる単位がタスクの大きさ(粒度)に制限されるため、並列化の効率も制限を受ける。
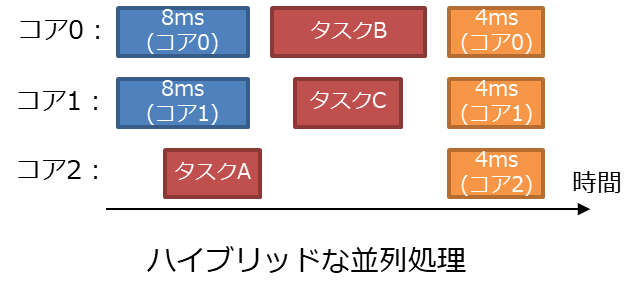
1.1.1.3 ハイブリッドな並列処理
前述のタスク内並列処理、タスク間並列処理を合わせたハイブリッドな並列処理も考えられる。
タスク内並列にしても、タスク間並列にしても、同時に実行可能な処理の量には限界がある。これは、後述する並列化の阻害要因が存在するためである。
それらの要因を排除しつつ、並列化効率を最大にするためには、下図のようなハイブリッドなタスク並列が必要になると考えられる。
1.1.2 タスク内で並列化する際の課題
タスク内並列処理では、タスクを記述するソフトウェアの中から並列に実行可能な箇所を抽出し、マルチコアに割り付ける。
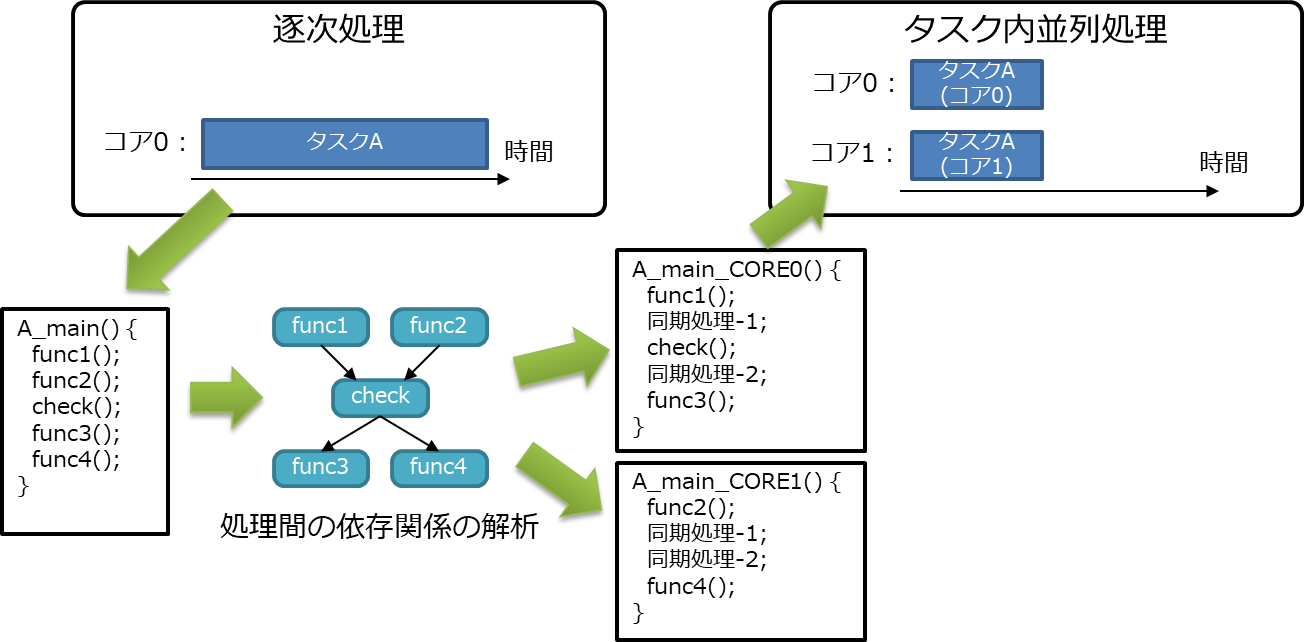
1.1.2.1 コア間の同期処理が必要な場合
- 図 4 は、タスクAの中の処理について、関数func1とfunc2、関数func3とfunc4が同時に実行できる(依存関係がない)ものと判断した例。
- 関数checkは前後の関数との依存関係があるため、別のコアに分割して割り当てるには、コア間の同期処理が必要になる。
1.1.3 ソフトウェアの並列化から性能確認、再設計までの流れ
ソフトウェアを並列化して性能を向上させることは、解決するべき課題が非常に多く、困難を伴う。
1.1.3.1 並列化の開発プロセス
ソフトウェアを並列化した後、性能を確認し、必要に応じて再設計を行う。並列化の工程では、自動並列化ツールなどを活用して作業効率の向上を図れる。
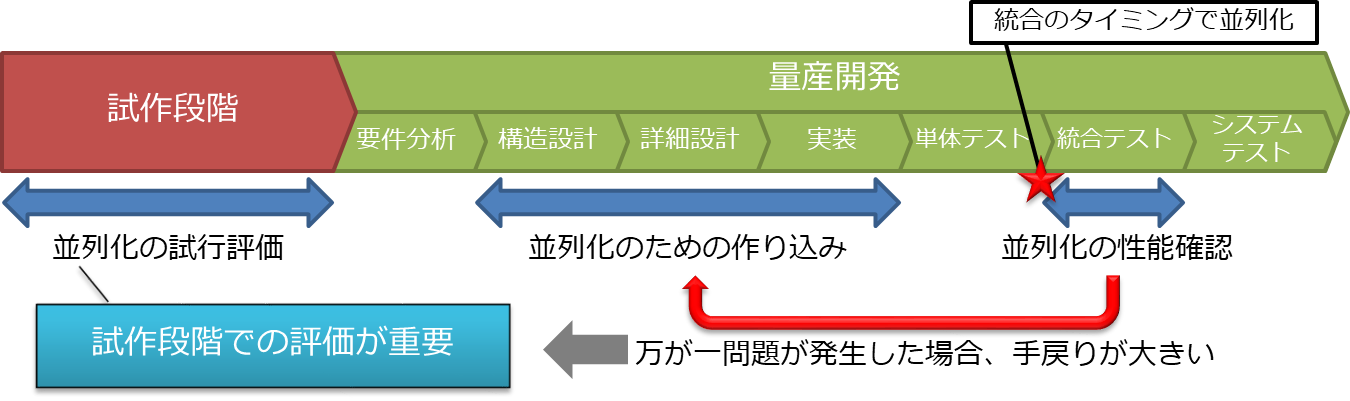
並列化によりソフトウェアの性能を向上させるには、局所的なソースコードへの対処だけでは不十分。大局的な情報が必要になる。そのため、ソフトウェア開発工程において、実装と単体テストの完了後に並列化を行い、統合テストやシステムテストの工程で性能を確認する。
統合テストの工程で性能上・品質上の問題が判明すると大きな手戻りが発生し、開発スケジュールや工数への影響が甚大になる。量産開発時の手戻りを防ぐためには、試作段階でどこまで精度の高い並列化の方針が立てられるかが非常に重要。
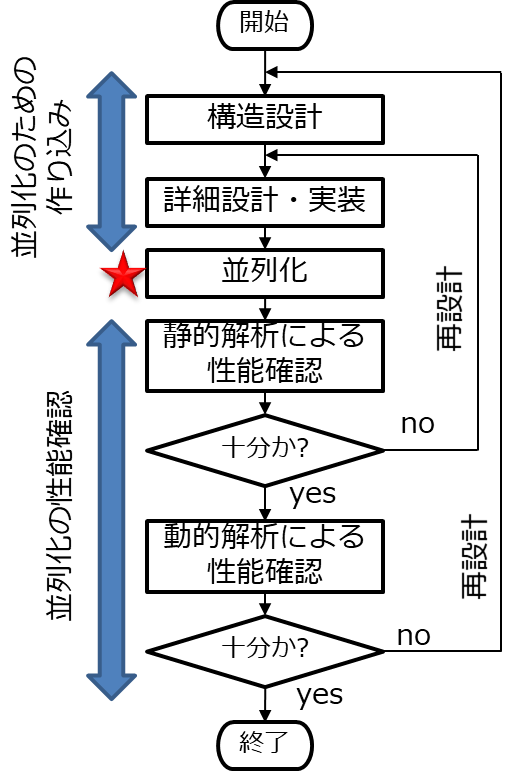
1.1.3.2 ソフトウェアの並列化のフロー
ソフトウェアの並列化のフローの概略は、以下のようになる。
「並列化」は、開発工程上の構造設計(アーキテクチャ設計)から詳細設計、実装にまで及ぶ可能性がある。
並列化した後の性能は、 1.1.4 以降で示す「静的解析で確認するべき項目」と「動的解析で確認するべき項目」の2段階で確認する。一般には、「静的解析による性能確認」に対する再設計は「詳細設計・実装」の工程への手戻りに、「動的解析による性能解析」に対する再設計は「構造設計」、もしくはシステム設計の工程への手戻りになる可能性が高い。
前項で述べたように、量産開発において構造設計や詳細設計の工程に立ち返ることは、極力避けたい。そのため、 図 6 と同等のフローを試作段階で適用し、並列化の課題を事前に解決しておくことが重要になる。
1.1.4 静的解析と動的解析で確認するべき事項
並列性能の向上のために確認するべき事項には、以下の項目がある。
1.1.4.1 静的解析で確認するべき項目
ソースコードや設計情報など、プログラムを実行させる前に分かる情報を用いて解析し、確認するべき情報。
ソフトウェアの依存関係:ソフトウェアの処理と処理の間の依存関係(順序関係)( 1.2.1 参照)
依存関係が判別できない要因:実行時にしか決まらない情報、設計情報として開示されていない情報など( 1.2.2 参照)
ソフトウェア構造上のボトルネック:並列化を考えるうえで障害となるソフトウェアの構造( 1.2.3 参照)
マルチコアへの割り当て:処理をマルチコアに分散して割り当てる上で確認するべき項目( 1.2.4 参照)
1.1.4.2 動的解析で確認するべき項目
評価ボードや量産ハードウェアなどでプログラムを実行させないと確認できない、もしくは確認が困難な情報。
並列処理の開始・終了による性能オーバーヘッド:並列処理に特有の開始・終了時のオーバーヘッド( 1.3.1 参照)
同期による性能オーバーヘッド:マルチコア間の依存関係(順序関係)を維持するために必要な同期処理に伴うオーバーヘッド( 1.3.2 参照)
メモリ配置の影響:マルチコア環境でのメモリ配置による並列性能への影響( 1.3.3 参照)
リソース競合:マルチコア間でリソースへのアクセスが競合することによる並列性能への影響( 1.3.4 参照)
1.2 静的解析による並列性能の確認とソフトウェアの再設計
次に、並列性能の向上のために確認するべき項目のうち、ソースコードや設計情報など、プログラムを実行させる前に分かる情報を用いた項目について説明する。
1.2.1 ソフトウェアの依存関係
ソフトウェアの依存関係には、制御の依存関係と変数(データ)の依存関係がある。ここでは、変数の依存関係の種類とその対処方法について述べる。
1.2.1.1 変数の依存関係
変数の依存関係には、変数の定義・参照関係の違いから、順依存、逆依存、出力依存の3種類がある。

順依存は、プログラムの自然な流れで発生する依存関係。解消するためには、プログラムのアルゴリズムの変更が必要になる。
逆依存と出力依存は、主に変数の使いまわしからくる依存関係。変数名を変えることにより、依存関係を解消できる。
1.2.1.2 逆依存の解消
新たな変数名を導入することで逆依存が解消する例を示す。

新たな変数を導入することで依存関係が解消し、並列実行が可能となるが、実行に必要となるメモリサイズが増えることに注意しなければならない。
1.2.2 依存関係が判別できない要因
プログラム内の変数の依存関係を解析する際、判別できない要因がいくつか考えられる。ここでは、代表的な要因とその対策を挙げる。

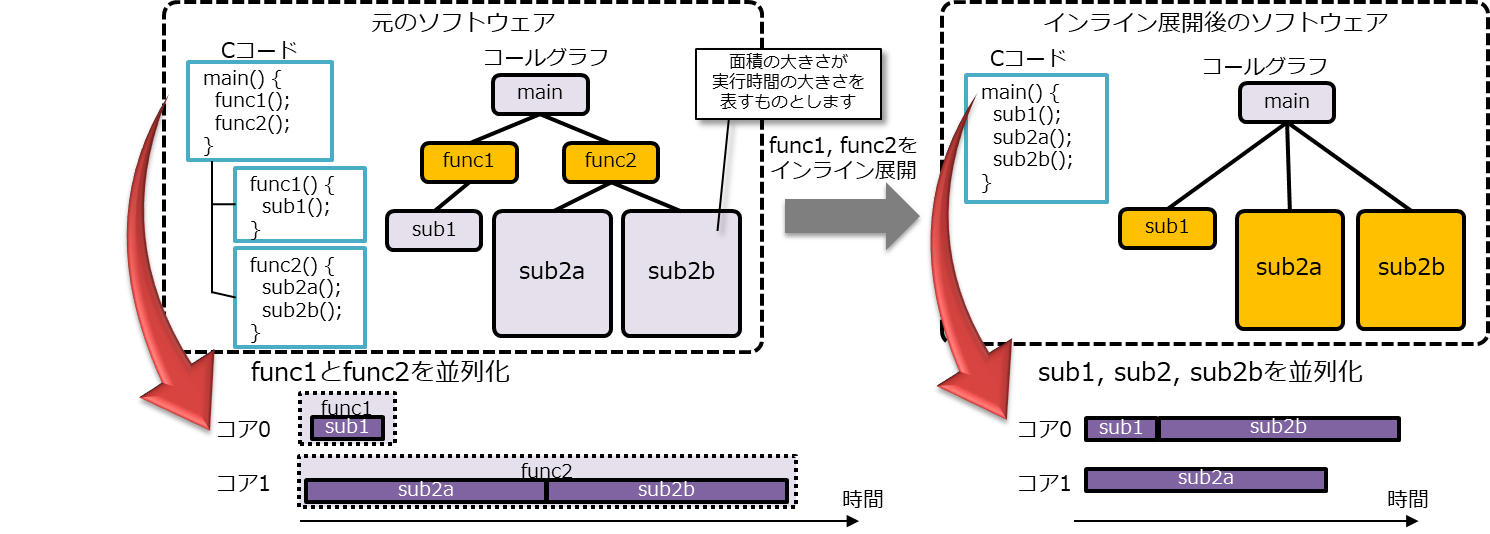
1.2.3 ソフトウェア構造上のボトルネック
論理的に並列性のある処理がソフトウェアの呼び出し構造の深い場所にあると、ソフトウェア構造が性能向上のボトルネックになることがある。
プログラムの論理的な意味を変更せずにプログラム構造を変更することで、並列性を抽出したり、より効率よく並列実行が可能な場合がある。
プログラム構造を変更する手段の一つとして、インライン展開がある。
1.2.4 マルチコアへの割り当て
1.2.1~ 1.2.3に示した課題を解決しても、マルチコアへの処理の割り当てによっては、並列化効率が向上しない場合がある。処理の割り当てについて、以下のような課題を検討する必要がある。
1.2.4.1 コアごとの処理量の均一化

図 7 では、各コアに割り当てる処理負荷が均一ではないため、コア1とコア2のCPU時間に無駄が生じてしまう。処理A~Cの負荷の総計=1,500に対し、コア0の処理Aの負荷=700が支配的になるため、並列化効率は2.14程度となっている。

図 8 のような理想的な割り当てを目指すには、処理負荷を均一にするための施策が必要。まず、性能向上のボトルネックになっている処理Aを分解することを検討するべきである。分解の手法としては、2-3で述べたインライン展開などのリストラクチャリングや、ループ処理の分割などが考えられる。
1.2.4.2 割り当ての最適化
図 9 左上のような依存関係と処理負荷のある五つの処理を、二つのコアに割り当てることを考える。
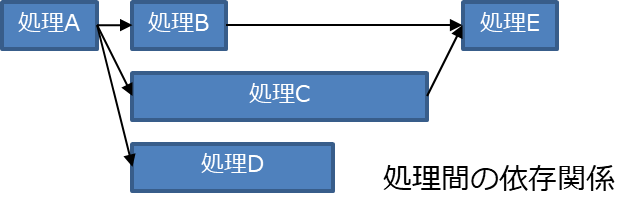
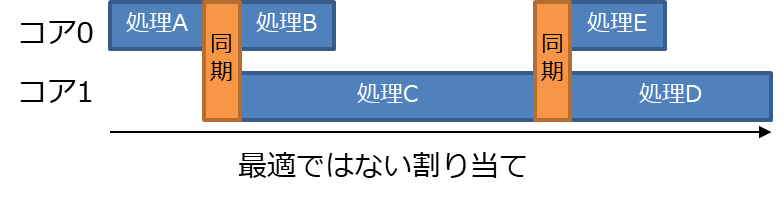
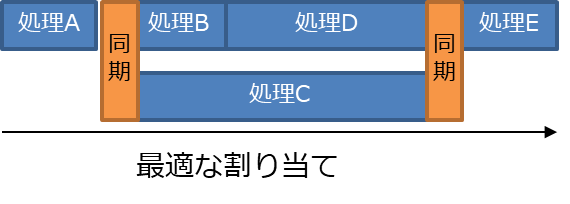
図 10 では、処理Dをコア1に割り当ててしまったため、最適な割り当てである右下の図よりも処理時間が増加している。依存関係の条件を満たす範囲で、 図 11 のような最適な割り当てを目指す必要がある。
この例では処理が5個と少ないため、最適な割り当てを行うのは容易だが、現実の組込みソフトウェアでは非常に多くの処理を対象とする必要がある。
- タスク間並列では、タスクの数の組み合わせを考慮する必要がある。
- タスク内並列では、分解能に従って処理の数はさらに増大する可能性がある。
非常に多くの処理を、限られた開発の時間内で最適に割り当てるのは難しい。自動並列化コンパイラは、最適に近い解を実用的な時間で得られる工夫がなされている。
1.3 動的解析による並列性能の確認とソフトウェアの再設計
最後に、並列性能の向上のために確認するべき項目のうち、評価ボードや量産ハードウェアなどでプログラムを実行させないと確認できない、もしくは確認が困難な項目について説明する。
1.3.1 並列処理の開始・終了による性能オーバーヘッド
タスクを新規に開始するには、通常、下記のような手順が必要であり、オーバーヘッドを伴う。
- (割り込みによる)タスクマネージャの開始
- 実行中のタスクの終了処理、または退避処理(プリエンプション)
- 新規タスクの開始
1.3.1.1 タスクの終了・起動
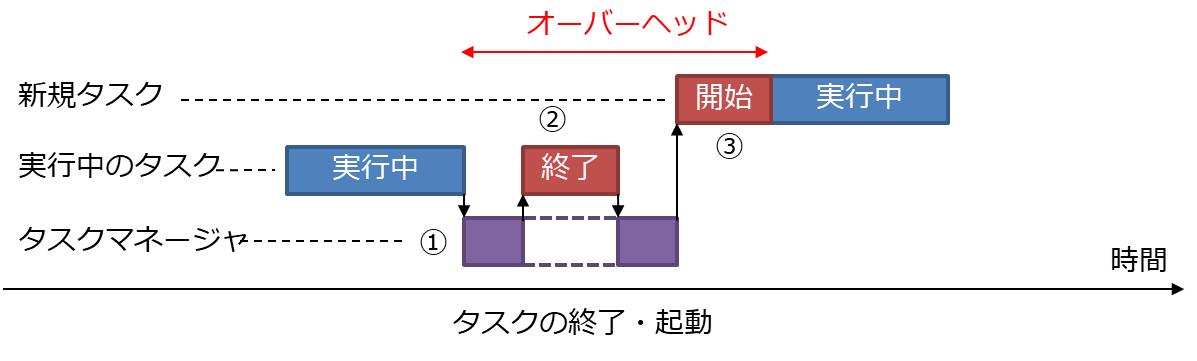
新規タスクをタスク内並列処理するには、上記のような通常のオーバーヘッド以外に、特有のオーバーヘッドを考慮する必要がある。
1.3.1.2 マルチコアにおけるタスクの終了・起動
並列処理の開始・終了に伴うオーバーヘッドの量は、タスクをどのように管理するか、というシステム設計に強く依存する。
ここでは、マルチコアの構成はマスタ(1コア)とスレーブ(複数コア)に分かれており、タスクマネージャ、およびタスクの開始・終了の動作はマスタコアが主導するものとする。
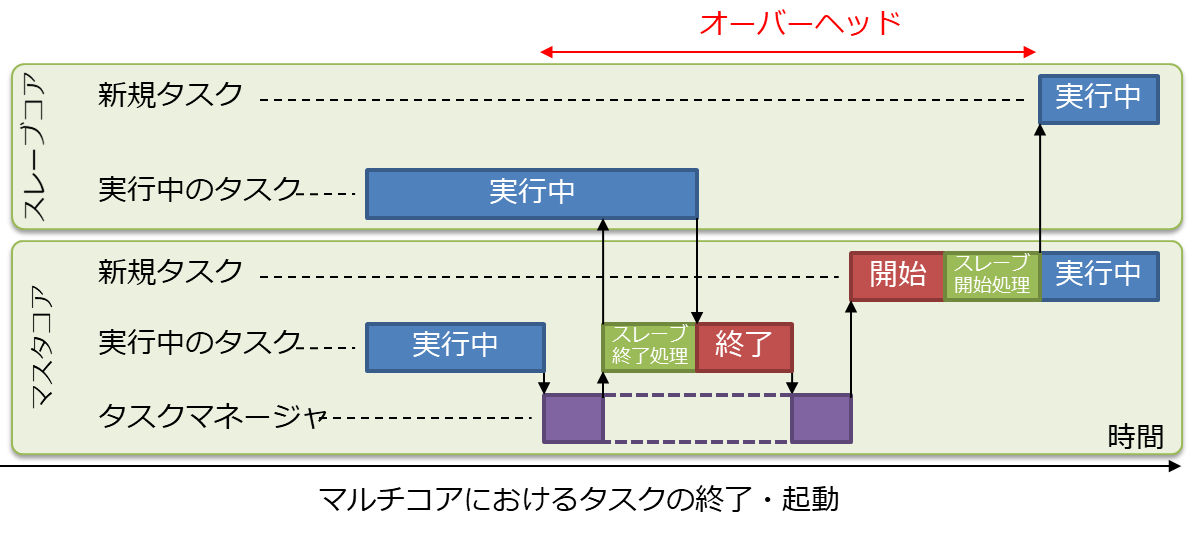
並列処理の開始・終了のオーバーヘッドを最小にするためには、下記のようなシステムレベルの施策が必要になる。
1.3.1.3 タスクマネージャの分散化
タスクマネージャがマスタコアでのみ動作する集中管理のシステムでは、タスクの遷移のたびにマスタコアの負荷が増加する。さらに、タスクマネージャの処理中にスレーブコアが実質的な処理を行えないため、並列処理の効率が悪化する。
タスクマネージャをマルチコア全体で分散処理し、タスク遷移の際のタスクマネージャの負荷を軽減する必要がある。
1.3.1.4 タスク遷移頻度の削減
タスクの開始・終了は、そもそもタスクを遷移させるために必要な処理である。例えば、タイマにより一定間隔で開始・終了するタスクに対し、周辺デバイスからの割込みを契機に非同期に処理しなければならない高優先のタスクが発生した場合、タスクを遷移することを考えなければならない。
シングルコアのシステムでは、一時にたかだか一つのタスクしか実行できないため、タスクの遷移が必須。しかし、マルチコアのシステムでは、1-1で述べたタスク間並列処理やハイブリッドな並列処理のように、依存関係のないタスクの並列実行が可能。マルチコアのシステム構成と静的なタスクの割り付けの改善により、タスク遷移の頻度を削減できる。
1.3.2 同期による性能オーバーヘッド
処理と処理の間の依存関係(順序関係)を維持し、かつマルチコア間に処理を分散配置するためには、コア間の同期処理が必須である。
1.3.2.1 コア間の同期処理
下図は処理間の依存関係をグラフで表しているものとする。処理1と処理2は別のコアで並列に実行できる。同じように、処理4と処理5も並列に実行できる。
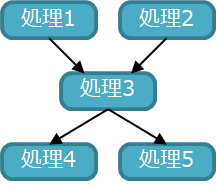
処理2と処理5を別のコアに割り当てた場合を考える。
処理1と処理2の実行時間に差があると、処理2の終了を待たずに誤って処理3を開始してしまう、という状況が起こりえる。

ソフトウェアを正しく動作させるためには、上記のように同期処理を挿入する必要がある。
シングルコアで実行する場合は不要な処理であり、並列化特有のオーバーヘッドとして考慮しなければならない。
1.3.2.2 同期処理の実現手法
同期処理を実現するには、以下のような手法がある。
- 同期フラグの実装方法による分類
- グローバル変数(コア間の共有変数)をフラグとして利用した同期処理
- 専用ハードウェアによる同期処理
- APIの違いによる分類
- リアルタイムOSなどで規定されたAPIを利用する同期処理
- ソフトウェア独自の同期処理
1.3.2.3 同期によるオーバーヘッドの縮小
同期による性能オーバーヘッドを縮小するために、以下を考慮する必要がある。
- 同期処理そのものの最適化
- グローバル変数へのアクセス時間や、専用ハードウェアの利用可能性を考慮した同期処理の実装方法を見直す。
- 同期処理の回数の削減
- ソフトウェアを分割するほど並列に実行できる箇所は増加するが、並列に実行できる処理の粒度は小さくなる。一方、同期処理はほぼ一定の時間を必要とする。さらに、並列に実行できる箇所が増えるほど、同期が必要な箇所も増加する。その結果、ソフトウェアの分割が進むほど、同期によるオーバーヘッドの割合は増大する。
- 並列性の向上と同期のオーバーヘッドの削減はトレードオフの関係。システムごとの同期処理の時間を見極めたうえで、最適なポイントを探る必要がある。
1.3.3 メモリ配置の影響
PCやサーバはもちろん、組込み用のSoCやマイコンにおいてもメモリの階層化やローカル化が進んでいる。マルチコアでは、各コアがアクセスするコードやデータの、メモリへの最適な配置を考えないと、シングルコアの場合よりも性能が悪化する、という事態も起こりえる。
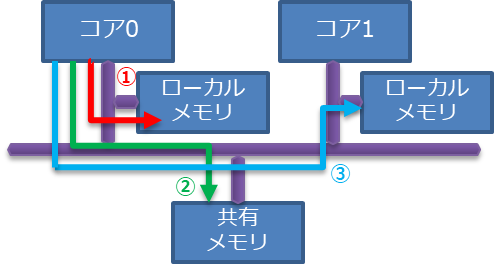
図 16 のようなハードウェア構成の場合、コア0からのメモリアクセスは下記の3通り。
- 自コアのローカルメモリへのアクセス
- 共有メモリへのアクセス
- 他コアのローカルメモリへのアクセス
ローカルメモリを搭載する最大の目的はアクセス速度の向上。コア0からの各メモリへのアクセス時間は、①<②<③となるのが一般的。
上記のようにメモリの階層化、ローカル化が進んだSoCやマイコンでは、下記のようなメモリ配置を実現する必要がある。
- コア0からのアクセス頻度が最も大きいデータを、コア0のローカルメモリに配置
- コア1からのアクセス頻度が最も大きいデータを、コア1のローカルメモリに配置
- コア間で共通にアクセスするデータは、共有メモリに配置
最適なメモリ配置のためには、コアごとのデータのアクセス頻度を測定する必要がある。自動並列化コンパイラなどのツールの中には、静的に解析できる範囲でアクセス頻度を算出できるものがある。
1.3.4 リソース競合
マルチコア環境では、各コアで共通のリソースへのアクセスが競合し、並列性能が阻害されることがある。
1.3.4.1 バスの競合
コアから、共有メモリや周辺デバイスへのアクセス経路が単一のバスに限られていると、バスの調整において競合し、性能が阻害される。
マルチレイヤ構成(マルチマスタ構成)可能なバスを採用するなど、システムレベルの対策が必要。
1.3.4.2 共有メモリの競合
1.3.3 では「コア間で共通にアクセスするデータは共有メモリに配置」という指針を示した。しかし、共有メモリへの各コアからのアクセスが頻発すると、メモリアクセスが競合し、性能が阻害される可能性がある。
共有メモリをアドレスドメインごとに分散する、あるいは共有メモリをマルチポートRAMで構成するなど、システムレベルの対策が必要。
1.3.4.3 周辺デバイスの競合
メモリだけでなく、SoC上の周辺デバイス(ペリフェラル)についても、アクセスが競合する可能性がある。
コアごとに機能を分割することにより、アクセス対象の周辺デバイスを分散させるようなソフトウェア設計が必要。
1.4 まとめ
マルチコアの性能を向上させるには、ソフトウェアを並列化しなければならない。ソフトウェアの並列化にはさまざまな粒度が考えられ、システムに合った構成を選択する必要がある。
並列化したソフトウェアに対して、まず、静的解析による並列性能の確認を実施する。並列性能を満たせない場合は、依存関係の解消やリストラクチャリングなどの再設計を実施する。
次の段階では、実機や評価ボードを用いた動的解析による並列性能の確認を実施する。並列性能の問題が判明した場合、システム設計やソフトウェアの構造設計を見直す必要がある。
並列性能不足による開発の手戻りを最小限にするため、試作段階の性能評価と並列化方針の確定が重要である。